Web Starter Kitのウリは沢山ありますが簡単にまとめると以下の8つです(多い!)
- マルチデバイスなボイラープレート式のレスポンシブデザインが使える
- ビジュアルデザインシステムでUIをデザインできる
- クロスデバイスな同期的な開発ができる
- デフォルトでライブリロードしてくれる(コーディングが反映される)
- パフォーマンスが最適化される(Minify JS/CSS/HTML)
- ビルトインなHTTPサーバが準備されている
- Webパフォーマンスの分析を行いレポートしてくれる環境付き
- Sassをサポートしている
STEP1: 環境構築
何はともあれ開発環境を整えます。
まずは、Web Starter Kitをダウンロードします。
$ git clone https://github.com/google/web-starter-kit.git $ cd web-starter-kit/app
次に開発ツールをインストールします。
必要な開発ツールはNode, Ruby, Sass gem, Guplの4つです。
順に入れていきます。(順番大事です)
Nodeはv0.10.x以上が必要です。ターミナルでnode -vを入力してバージョンを確認します。
インストールしていない場合はNode.js本家からインストールして下さい。
Rubyは1.8.7以上のバージョンが必要です。ターミナルでruby -vを入力してバージョンを確認します。さらにgem --versionがエラーなく実行できたらOKです。Rubyのダウンロード&インストールはRuby本家からどうぞ。
次にSassのインストールです。sass -vでバージョンを確認し3.3.x以上であることを確認して下さい。インストール方法はコチラを参照。
最後にGulpのインストールです。Gulpは高速で効率的でシンプルなビルドシステムだそうです。gulp -vでバージョンを確認し、3.5.x以上が必要です。
新規インストールが必要な方は以下のコマンドでインストールできます。
$ sudo npm install --global gulp
これで開発ツールのインストールが完了です。
最後に、これらのツールを使って開発環境を構築します。
Web Starter Kitのディレクトリに移動して依存ライブラリなどをインストールします。
$ cd web-starter-kit $ sudo npm installnode.jsが全部やってくれるので上のコマンド一発で完了です。便利!
STEP2: とりあえず動かしてみる
まずはプロジェクトをビルドする。
$ cd web-starter-kit/app $ gulpこのコマンドが成功するとweb-starter-kit/distにビルド結果が格納されます。基本的な開発はこのとおりです。app内を編集してgulpしてdistを見る。
dist内の表示方法はサーバを通して見ると良いでしょう。コレも簡単。
$ cd web-starter-kit $ gulp serveこれにより勝手にブラウザが起動してhttp://localhost:3000が表示されます。これはdistディレクトリのindex.htmlが表示されています。サーバ起動しておくとweb-starter-kit/app内を監視し、変更あれば先のビルドを自動で行い、ブラウザの表示も自動で変更されます。いわゆるライブリロードというやつです。
表示もちゃんとレスポンシブになっています。
 |
| PCサイズのUIデザイン |
 |
| モバイルサイズのUIデザイン |
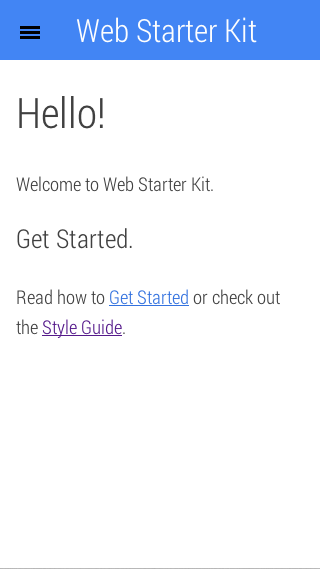 |
| iPhoneエミュレートでのUIデザイン |
 |
| Nexus5もiPhoneと同じUIになる |
iPad 3/4も同じ。画面が大きいので2カラムなレイアウトにするとかPCと同じレイアウトでも良いのでは…
 |
| iPad 3/4のUIデザインはモバイルと同じ感じ |
Nexus7もiPad 3/4と同じ感じだったけど、Nexus10はPCと同じレイアウトになった。
 |
| Nexus10はPCのUIと同じデザイン |
 |
| Motorola XoomによるUIデザイン |
STEP3: Web Starter Kitを使って開発してみる
サーバが起動した状態でどんどん開発をすすめます。
web-starter-kit/app内のindex.htmlやらcssなどを修正します。
すると勝手にビルドがはじまり、表示しているページが自動でリロードされ、コーディングした内容がどんどん反映されていくのが分かります。
例えばヘッダーの色を変更してみます。app/styles/main.cssを編集して、保存すると自動でビルドが始まり、すぐに仕上がりが確認できます。
 |
| main.cssを変更して開発フローを確認 |
なお、CSSの記述が規約違反をした場合、gulpがエラーで停止します。その場合、CSSを修正してからgulp serveコマンドで再実行します。
開発ついでに、iPadの画面UIがモバイルと同じくdrawer navigationを利用していたのが微妙だなぁと感じたので、PCと同じUIによせてみます。
やることはとても簡単で、main.cssのメディアクエリー箇所の1200pxとなっているところを1024pxにするだけです。
メディアクエリーの分け方はとてもシンプルで3通りです。
- デフォルトがモバイル
- min-device-width: 1200px がラージスクリーン(PCとか)
- min-device-width: 1200px and max-width: 800px (PCのnarrow表示)
今回はiPadもPC表記にしたいので2つ目のメディアクエリーの1200pxを1024pxにすればOKです。
 |
| iPadのUIをPCと同じにした |
以上がGoogleのWeb Starter Kitをサクッと使ってみた感じです。もうちょっと使ってみて面白い発見があれば別のエントリーで報告します。